Tenka1 Programmer Beginner Contest 2019感想戦
コンテストやったきりで復習しないマンなので,
blogに書くことによって強制的に復習するライフハック()を実践していく.
言い訳をする気はないけど(ちょっとある),
今回妙にメチャ回答の表示とか鯖側の処理が遅かった気がする.....
Tenka1 Programmer Beginner Contest 2019
A - On the Way
https://atcoder.jp/contests/tenka1-2019-beginner/tasks/tenka1_2019_a
解けた.
A, B, C = map(int, input().split())
if(A < C < B or A > C > B):
print('Yes')
else:
print('No')
正直言うと,Pythonらしい綺麗なコードですねぇ(ニヤニヤ)と思って解いてた
彼はこのとき,後の絶望を予測することは出来なかった.....
B - *e**** ********e* *e****e* ****e**
https://atcoder.jp/contests/tenka1-2019-beginner/tasks/tenka1_2019_b
解けた.
N = int(input())
S = list(input())
K = int(input())
for i in range(N):
if(S[i] != S[K-1]):
S[i] = '*'
print(''.join(S))
特に何にもない
リスト内包表記を使ってイキる気もなし
C - Stones
https://atcoder.jp/contests/tenka1-2019-beginner/tasks/tenka1_2019_c
解けなかった....
最後に提出した残骸
N = int(input())
S = list(input())
flag = False
count_w = 0
count_b = 0
count = 0
S_map = []
for i in S:
if(i=="."):
count += 1
S_map.append(count)
else:
S_map.append(count)
ans = []
for i in range(N):
if(i == 0 or S[i-1] == "." and S[i] == "#"):
if(i != 0):
left_white = S_map[i]
left_black = i - left_white
else:
left_white = 0
left_black = 0
if(i != N-1):
right_white = S_map[-1] - S_map[i]
right_black = (N-i-1) - right_white
else:
right_white = 0
right_black = 0
ans.append(min(left_white+right_white, left_black+right_black, left_black+right_white))
print(min(ans))
一回目の提出で「まあ,今回結果見れるまで時間かかるし,どうせACだし確認しなくていいや」と思ってD問題に移行してしまったorz
途中やっぱ確認しとくかと思ってテストケースの下5つがWAになっているのを確認して,左側白で右側黒のパターンを間違えているのに気づいたのは良かった
そこで綺麗に書き直せば良かったのに,前のクソコードを引き継いで書いたせいで,バグ残りまくりで無事死亡
ちゃんと書き直したら通りました.....
import numpy as np
N = int(input())
S = list(input())
S_map = [1 if i=="." else 0 for i in S]
cumsum = np.array(S_map).cumsum()
cumsum = np.insert(cumsum, 0, 0)
ans = []
for i in range(N+1):
if(i == 0 or i == N or S[i-1] != S[i]):
if(i != 0):
left_white = cumsum[i]
left_black = i - left_white
else:
left_white = 0
left_black = 0
if(i != N):
right_white = cumsum[-1] - cumsum[i]
right_black = (N - i) - right_white
else:
right_white = 0
right_black = 0
ans.append(min(left_white+right_white, left_black+right_black, left_black+right_white))
print(min(ans))
D - Handstand
https://atcoder.jp/contests/tenka1-2019-beginner/tasks/tenka1_2019_d
解けなかった.....
なんにもわからん
解説読んだらDPで解けるらしい....
誰かのコードを参考にしようと思ったけど,BeginnerでPython3使ってAC出してる人いないんだが
Beginnerじゃないほうでも居なかったけど,PyPy3でAC出してる人はいた
n_knuuさんのコード
綺麗だ......
結果

AtCoder Beginner Contest 124感想戦
コンテストやったきりで復習しないマンなので,
blogに書くことによって強制的に復習するライフハック()を実践していく.
ABC 124
A - Buttons
https://atcoder.jp/contests/abc124/tasks/abc124_a
解けた.
A, B = map(int, input().split()) max_num = max([A, B]) if(abs(A-B) >= 1): print(max_num*2 - 1) else: print(max_num*2)
解説見てたら max(A*2-1, B*2-1, A*B) みたいな感じがコメントで流れてきて,それも良いなぁと思った.
B - Great Ocean View
https://atcoder.jp/contests/abc124/tasks/abc124_b
解けた.
N = int(input())
Hn = list(map(int, input().split()))
count = 0
for num, i in enumerate(Hn[1:]):
if(max(Hn[:num+1]) <= i):
count += 1
print(count + 1)
なんか,書いたら解けてた.未だに問題よくわかってない説ある.
C - Coloring Colorfully
https://atcoder.jp/contests/abc124/tasks/abc124_c
解けた.
S = list(map(int, input()))
start0 = [0, 1]*(len(S)//2+1)
start1 = [1, 0]*(len(S)//2+1)
ans = [0, 0]
for i, j, k in zip(S, start0, start1):
if(i != j):
ans[0] += 1
if(i != k):
ans[1] += 1
print(min(ans))
最初は,
for i, char in S:
if(i%2 == char):
count += 1
みたいな感じで書こうかと思ってたんだけど,思考力を奪われたのでlistを用意した.
D - Handstand
https://atcoder.jp/contests/abc124/tasks/abc124_d
解けなかった.....
0の連続した長さ,1の連続した長さの累積和をコネコネして,出来そうなんだけど出来なかった.....
Twitterで「0始まりはウザイので長さ0最初に付け足して,1始まりと同じにした」的なツイートに気づかされた.
終わった後,ゲームしてたけど悔しくてまたチャレンジしてみたら出来た........
import numpy as np
N, K = map(int, input().split())
S = input()
len0 = [len(i) for i in S.split('1') if (len(i)) != 0]
len1 = [len(i) for i in S.split('0') if (len(i)) != 0]
lens = np.zeros(len(len0)+len(len1), dtype=np.int)
if(int(S[0])==0):
lens[::2] = len0
lens[1::2] = len1
else:
lens[::2] = len1
lens[1::2] = len0
lens = np.cumsum(lens)
if(S[0] == "0"):
lens = np.insert(lens, 0, 0)
lens = np.append(lens, [lens[-1]]*(K*2))
if(K >= len(len0)):
print(len(S))
else:
ans = []
max_num = 0
for first, i in enumerate(range(K*2, len(lens), 2)):
if(first == 0):
ans = lens[i]
else:
ans = lens[i] - lens[i-(K*2)-1]
if(ans > max_num):
max_num = ans
print(max_num)
う~ん.....
しゃくとり法でやると良い感じに出来るっぽいので,そっちも書けるようにしたい感isある.
後で見てみる.
2019/04/14 (どこかで拾ったD問のしゃくとり法を使ったコード)
n, k = map(int, input().split())
s = input()
s += 'X'
i = 0
j = 0
zero = 1 if s[0] == '0' else 0
ans = 0
while j < n:
if zero <= k:
ans = max(ans, j - i + 1)
if s[j] == '1' and s[j + 1] == '0':
zero += 1
j += 1
else:
if s[i] == '0' and s[i + 1] == '1':
zero -= 1
i += 1
print(ans)
理解のために,途中の変数の動きを表示してみた.
入力は入力例2の
14 2 11101010110011
14 2 11101010110011 i j s zero ans 0 1 1 0 1 0 2 11 0 2 0 3 111 1 3 0 4 1110 1 4 0 5 11101 2 5 0 6 111010 2 6 0 7 1110101 3 7 1 7 110101 3 7 2 7 10101 3 7 3 7 0101 3 7 4 7 101 2 7 4 8 1010 2 7 4 9 10101 2 7 4 10 101011 3 7 5 10 01011 3 7 6 10 1011 2 7 6 11 10110 2 7 6 12 101100 2 7 6 13 1011001 2 7 6 14 10110011 2 8 8
実際に使いこなせるかは置いておいて,何となくはわかった.
アルゴリズムってすごいニャー.....
結果

CUDA10.0とPyTorchをWindows10+Anaconda環境にインストールする
手間取ったので、インストールする流れを残しておく
CUDAのインストール
CUDAの公式サイトから、インストーラをダウンロードする
プラットフォームに合わせてダウンロード
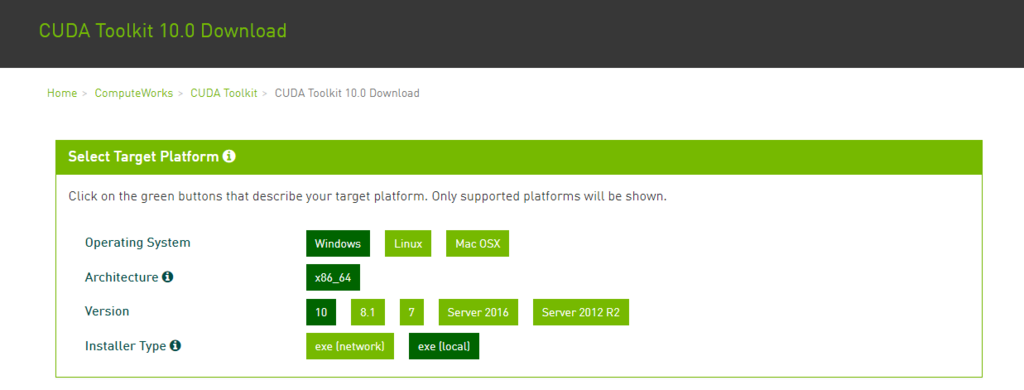
自分はインストーラ(2GB)をlocalに落とすのに2~3時間かかった
インストーラに言われるがままにインストール...
失敗した
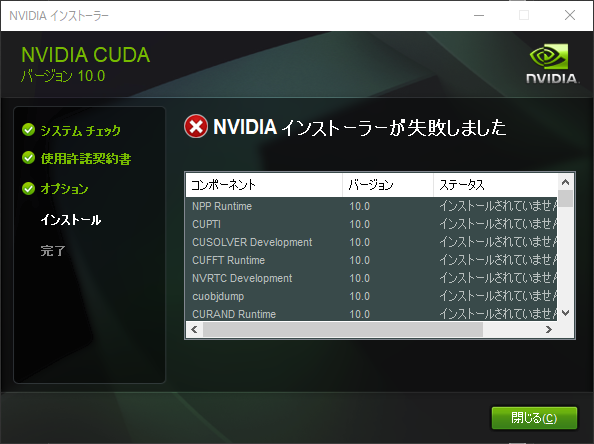
解決法
色々調べたところ、全てのNVIDIA製品をアンインストール、その後CUDAのインストールをすると治るという記事を複数見つけたが、自分はこの方法で解決した。(NVIDIAドライバとCUDAのバージョンの相性の問題っぽい)
グラボのドライバーを最新版にアップデート

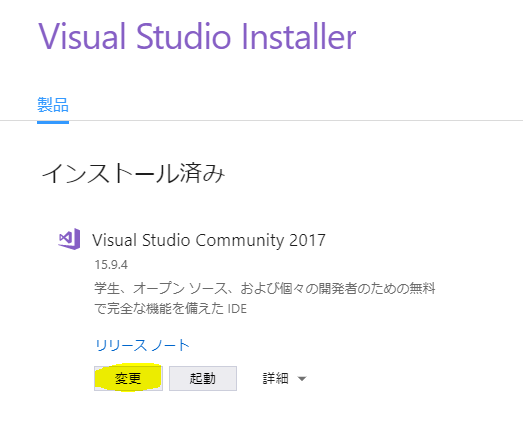
Visual Studio の Windows 10 SDK のコンポーネントをインストールする
- Visual Studio Installer から現在インストールされている製品の下にある変更ボタンをクリック
VS設定1 - ワークロードのユニバーサルWindowsプラットフォーム開発をクリックすると右に出てくるWindows 10 SDK にチェックを入れる(自分は全部入れたが1つでも良いかもしれない)
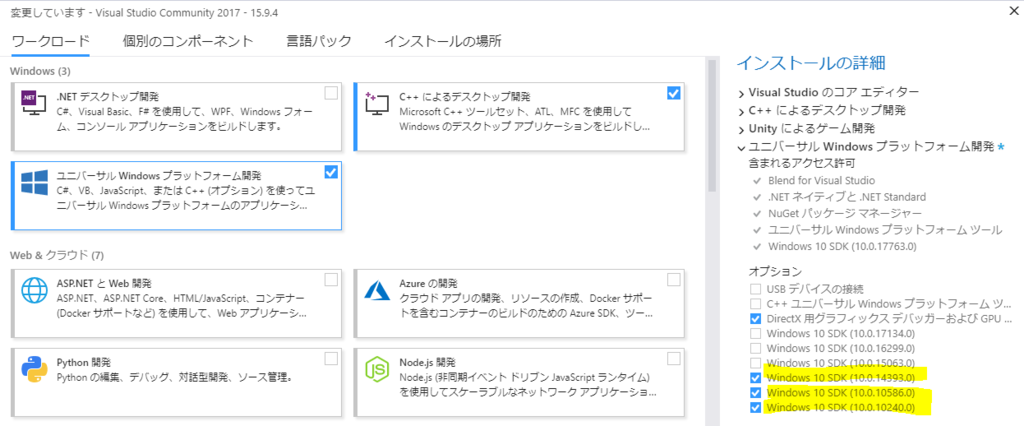
VS設定2
CUDAがインストール出来たか確認
インストールが終わったら、コマンドプロンプトから nvcc コマンドを実行してバージョン情報が出るかを確かめる。
>nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2018 NVIDIA Corporation Built on Sat_Aug_25_21:08:04_Central_Daylight_Time_2018 Cuda compilation tools, release 10.0, V10.0.130
PyTorchのインストール
PyTorchの公式サイトからインストールするために使うコマンドを調べる
自分が調べたとき(2018/12/14)は、
の場合は以下のコマンドを使えと言われた。
conda install pytorch torchvision cuda100 -c pytorch
自分は30分程度でインストールが終わった

PyTorchがインストール出来たか確認
PyTorch公式のtutorialsから適当なプログラムをコピペ、実行出来るか確認する。
自分はシンプルなNNのサンプルを動かしてみた。ソースは以下。
# -*- coding: utf-8 -*-
import torch# N is batch size; D_in is input dimension;
# H is hidden dimension; D_out is output dimension.
N, D_in, H, D_out = 64, 1000, 100, 10# Create random Tensors to hold inputs and outputs
x = torch.randn(N, D_in)
y = torch.randn(N, D_out)# Use the nn package to define our model as a sequence of layers. nn.Sequential
# is a Module which contains other Modules, and applies them in sequence to
# produce its output. Each Linear Module computes output from input using a
# linear function, and holds internal Tensors for its weight and bias.
model = torch.nn.Sequential(
torch.nn.Linear(D_in, H),
torch.nn.ReLU(),
torch.nn.Linear(H, D_out),
)# The nn package also contains definitions of popular loss functions; in this
# case we will use Mean Squared Error (MSE) as our loss function.
loss_fn = torch.nn.MSELoss(reduction='sum')learning_rate = 1e-4
for t in range(500):
# Forward pass: compute predicted y by passing x to the model. Module objects
# override the __call__ operator so you can call them like functions. When
# doing so you pass a Tensor of input data to the Module and it produces
# a Tensor of output data.
y_pred = model(x)# Compute and print loss. We pass Tensors containing the predicted and true
# values of y, and the loss function returns a Tensor containing the
# loss.
loss = loss_fn(y_pred, y)
print(t, loss.item())# Zero the gradients before running the backward pass.
model.zero_grad()# Backward pass: compute gradient of the loss with respect to all the learnable
# parameters of the model. Internally, the parameters of each Module are stored
# in Tensors with requires_grad=True, so this call will compute gradients for
# all learnable parameters in the model.
loss.backward()# Update the weights using gradient descent. Each parameter is a Tensor, so
# we can access its gradients like we did before.
with torch.no_grad():
for param in model.parameters():
param -= learning_rate * param.grad
備忘録的な日記を初めてみた
日記始めました
自分がプログラム書いてるときとか,いろんなサイトにお世話になるけど,見るだけで自分からアウトプットしてこなかったので,しようかなと思って日記を初めてみた.
今までに一回ブログを書こうと思って自前で静的サイトを用意して書いたけど,長続きしなかった.今回は細く長くで良いので,続けていきたいと思う.
日記の内容は,最近ハマってるkaggleとかの機械学習で自分が調べたこととか,自分が何かをするときに調べたこととかをまとめる感じにしようと思う.